![]()
Audious is a virtual assistant for music collections. Amongst other things, it provides the ability to manage albums by indicating the ones which are not in playlists. It also gives detailed statistics about a music collection, such as the number of artists and albums or the overall duration of a music category. It can also be used to sanitize playlists by showing corrupted or missing songs, and can export playlists in different formats, such as FLAC or MP3.
🎶
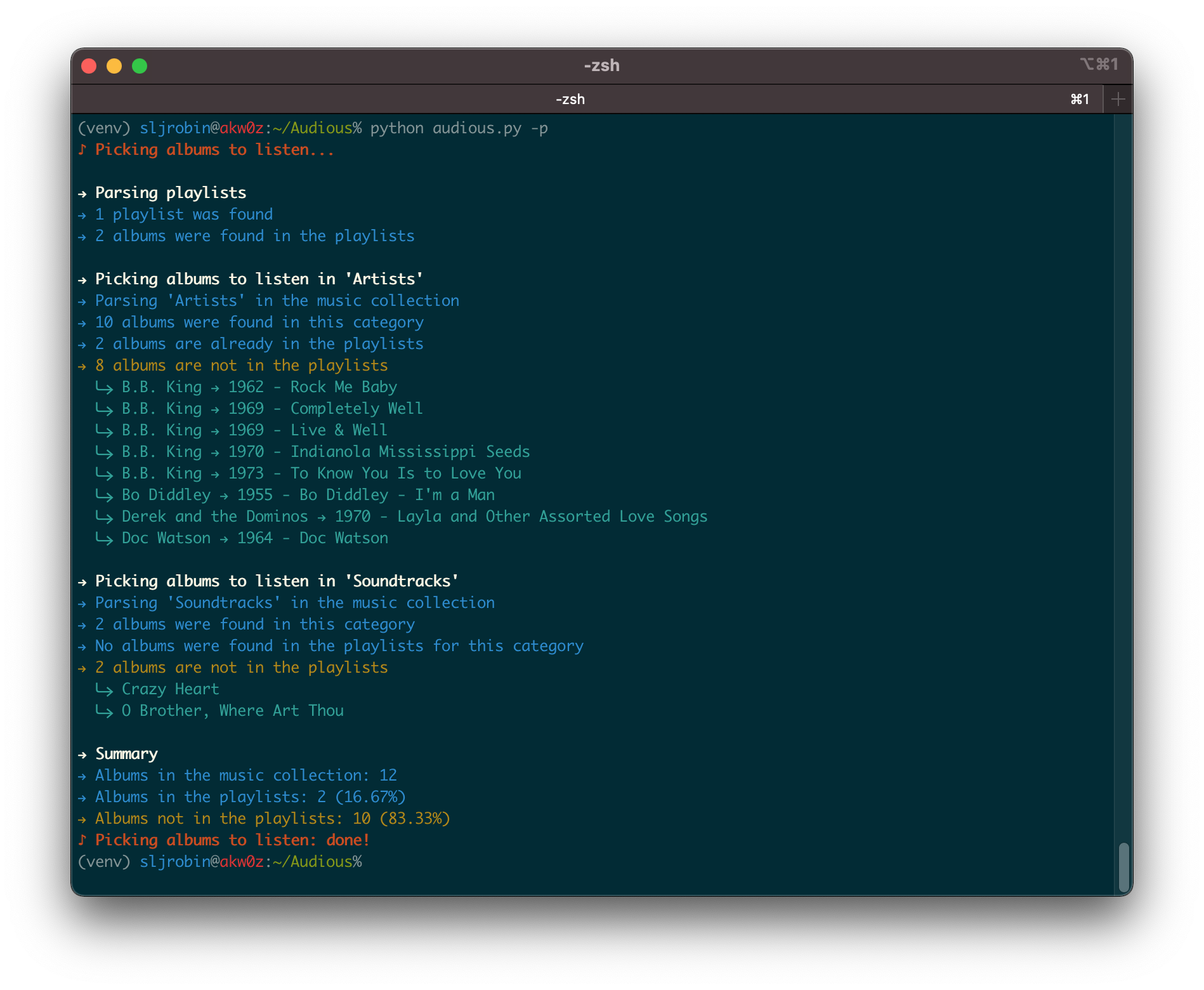
The more your music collection will grow, the more it will be difficult to remember which albums and songs you liked or listened to. Playlists are there to help us reminding which songs or albums we liked. But there might be albums that you didn’t place in a playlist. Audious will help you managing the albums that are not present in your playlists.

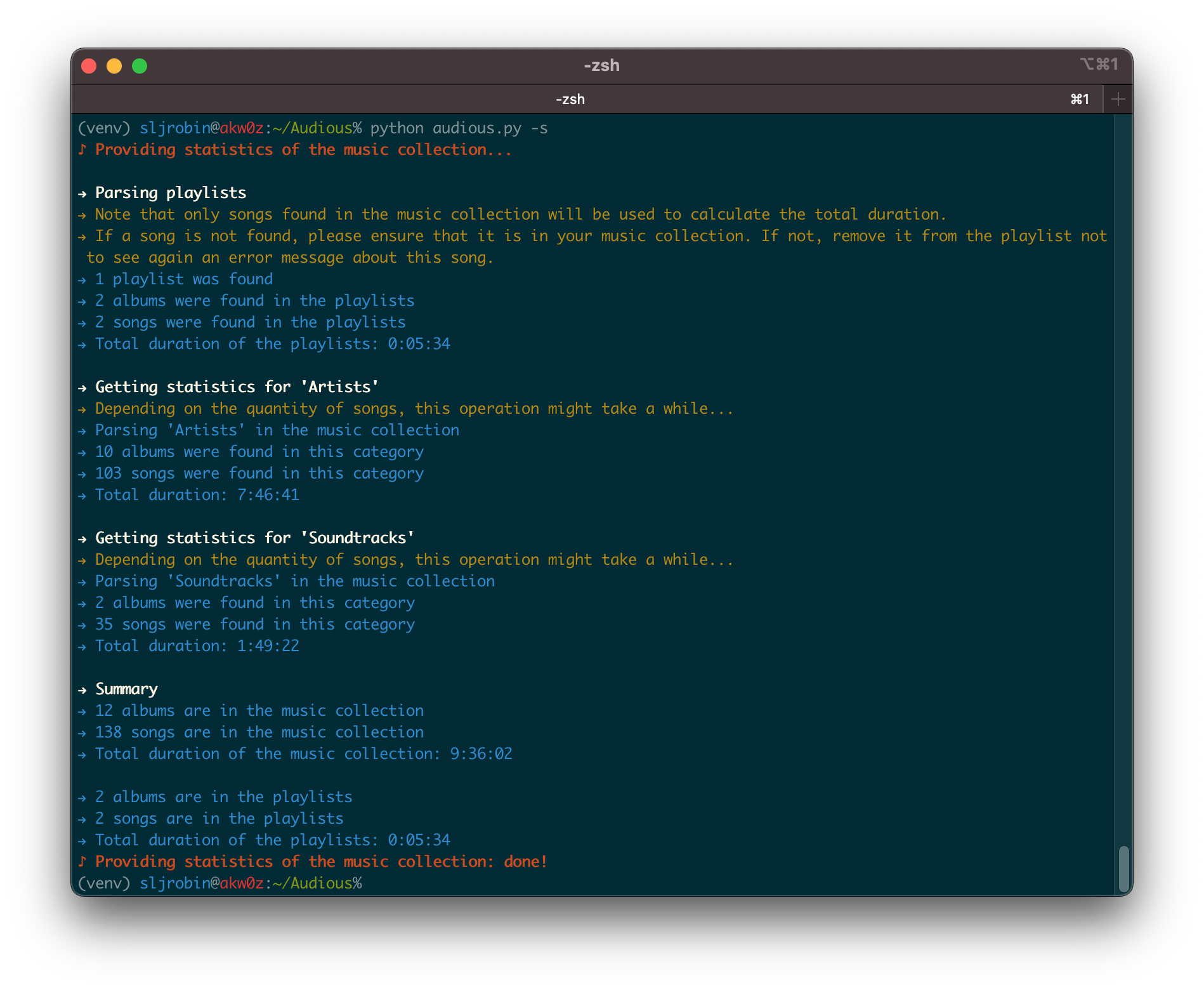
Having information about the song currently being played or even the year of the album you want to listen to is easy. However, getting the number of artists and albums, or how finding long it would take you if you wanted to listen to your entire music collection, it’s a different story. Audious will give you statistics about your music collection as well as your playlists.

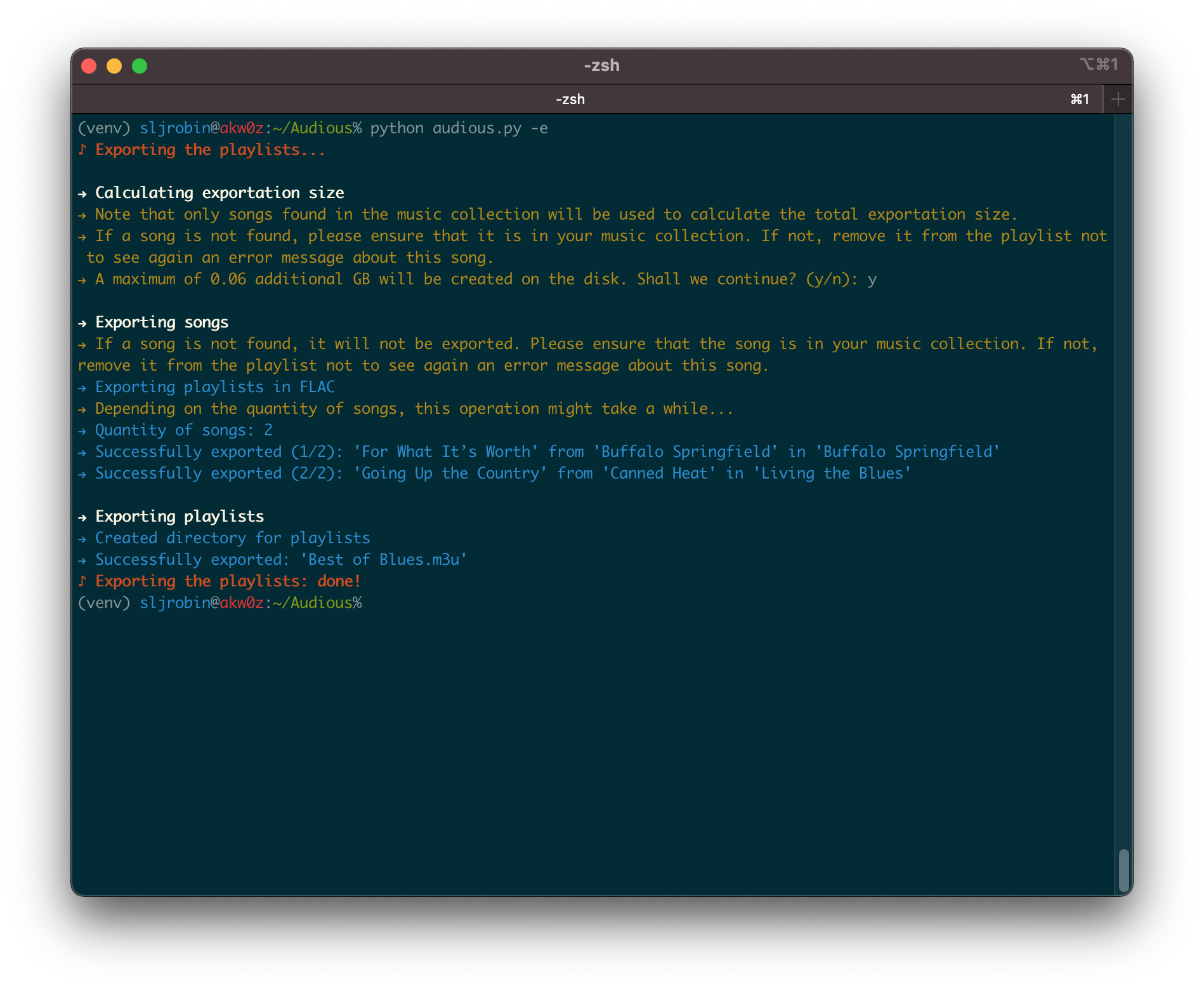
Nowadays, space is cheap. But lossless music is still demanding in size. Having your entire music collection with you all the time on a phone might be impossible. Audious will export all the songs of your playlists and ensure that your favorite songs will always be with you.

🎶
- Getting started: This section provides everything that is required to install Audious. It also shows how to setup it properly.
- Tips: Several tips are given in this section to have a better user experience.
- For Developers and Audiophiles: Audious has been designed as an open source project since day 1. This section clarifies the tool’s internals, explaining how to generate the source code documentation, and how the MP3 conversion is performed during the exportation process.
- About: The origin of the project and the different licenses are detailed in this section.
🎶
Without music, life would be a mistake.
— F. Nietzsche
- A basic knowledge of lossless and lossy audio formats
- A command line
- Python 3
- FFmpeg, which includes the FLAC and LAME packages
- A music collection with FLAC songs
- M3U playlists
- A wish to organize a music collection with playlists
- Install FFmpeg and LAME on the OS:
- On macOS:
brew install ffmpeg lame - On Linux (Debian-based):
sudo apt install ffmpeg lame
- On macOS:
- Clone this repository:
git clone https://github.com/sljrobin/Audious - Go to the Audious directory:
cd Audious/ - Create and activate a Python virtual environment:
python3 -m venv venvsource ./venv/bin/activate
- Install the requirements with pip3:
pip install -r requirements.txt
- A preferences file, named
preferences.json, is available under apreferences/directory located at root of the repository. It needs to be properly configured before running Audious for the first time. - The file is presented as follow:
{
"collection": {
"root": "",
"playlists": "",
"music": {
"artists": "",
"soundtracks": ""
}
},
"exportation": {
"root": "",
"playlists": "",
"format": ""
}
}- As it can be seen above, the file contains two main keys,
collectionandexportation.
The collection key gives details about the music collection:
rootis the absolute path of the directory where is located the music collectionplaylistsis the directory containing all the playlistsmusicgives the different categories of the music collection. For instance:artistsis the directory that contains all the Artists of the music collectionsoundtrackson the other hand, contains only soundtracks- Other music categories can be added under the
musickey (e.g."spoken word": "Spoken Word/") - The
artistsandsoundtrackskeys are not mandatory, however, at least one key is required
- Note: all given directories should have an ending
/(e.g.Artists/, and notArtists)
For instance, let’s suppose that a simple music collection is structured as follow:
Collection/
├── Artists/
├── Playlists/
└── Soundtracks/
The collection key in preferences.json should be edited as shown below:
"collection": {
"root": "/Users/<username>/Music/Collection/",
"playlists": "Playlists/",
"music": {
"artists": "Artists/",
"soundtracks": "Soundtracks/"
}The exportation key gives details about the playlists exportation:
rootis the absolute path of the directory where will be located the exported songs and playlistsplaylistsis the directory containing all the exported playlistsformatis the format song for the playlists exportation; only two options are available:flacandmp3- Note: all given directories should have an ending
/(e.g.Artists/, and notArtists)
For instance, let’s suppose that we create an Export/ directory in the Collection/ and we want to export all the songs of the playlists in FLAC; the exportation key in preferences.json should be edited as shown below:
"exportation": {
"root": "/Users/<username>/Music/Collection/Export/",
"playlists": "Playlists/",
"format": "flac"
}- Ensure first the Python virtual environment is enabled by running
source ./venv/bin/activate - Run Audious:
python audious.py --help
% python audious.py --help
usage: audious.py [-h] [-e] [-p] [-s]
optional arguments:
-h, --help show this help message and exit
-e, --export Export the playlists in FLAC or in MP3
-p, --pick Pick the albums from the music collection that are not in the playlists
-s, --stats Provide statistics of the music collection and the playlists
- Everything is now ready!
Because Audious is capable of parsing big music collections, the generated outputs might be relatively long. As a result, it might be difficult to have a quick glance at the statistics of a category or at the albums that were picked without scrolling.
An easy way to handle this scrolling issue is to combine Audious with the less command, as shown in the examples below:
python audious.py -s | less -Rpython audious.py -p | less -R
Press the space bar to switch to the next page on the terminal.
Hidden files
Hidden files on Linux or macOS are beginning with a dot (.). For instance, macOS creates lots of these files, called resource forks. As a result, an album with a song called 08 - High Voltage.flac might also contain a hidden file name ._08 - High Voltage.flac.
Audious is capable of handling these hidden files; it will indicate that it is not a valid file and does not contain any valid metadata. Nevertheless, having these files might generate a lot of noise in Audious outputs with plenty of errors (e.g. The following song could not be parsed and will be ignored: [...]).
To recursively remove these files and have clean outputs, go to the root of the music collection and use the following commands (Source):
- To only display hidden files in the music collection:
find /<path to music collection> -name '._*' -type f- To delete hidden files in the music collection:
find /<path to music collection> -name '._*' -type f -delete- The source code of Audious has been thoroughly documented in order to help people adding new features or simply improving the code.
- Because the code is commented, generating a documentation becomes easy.
- Amongst most popular solutions, we recommend using pydoc for the documentation generation process.
- Examples:
- Snippet of the documentation for the
lib/collection.pyclass:
NAME
collection
CLASSES
builtins.object
Collection
class Collection(builtins.object)
| Collection(display, preferences)
|
| Methods defined here:
|
| get_category_albums(self, category_songs)
| Open a category in the music collection and get a list of all the albums contained in this category.
| Handle macOS hidden files. Check the number of albums in the music category as well as in the music collection.
| Increment the total.
|
| :param list category_songs: list of songs contained in a music category.
| :return list category_albums: list of albums contained in a music category.
|
| get_category_songs(self, category, path)
| Open a category in the music collection and get a list of all the songs contained in this category. Select
| only .mp3 and .flac files with a regex.
|
| :param str category: the music collection category name.
| :param str path: the path where the music collection category is located.
| :return list category_songs: list of songs contained in a music category.
[...]
- Ogg format offers a better sound quality compared to the MP3 format. (Source)
- The MP3 format was chosen as the secondary format in the exportation options. This decision was made to ensure a better compatibility with devices (e.g. vintage audio systems, etc.).
- A list of all FFmpeg parameters can be obtained with
ffmpeg --help. - The MP3 conversion is performed via FFmpeg with the following command:
ffmpeg -v quiet -y -i <song.flac> -codec:a libmp3lame -qscale:a 0 -map_metadata 0 -id3v2_version 3 <song.mp3>- The parameters that were used are detailed below. They were carefully selected by following the FFmpeg MP3 Encoding Guide.
-v quiet: does not produce any log on the console-y: overwrites output files-i <song.flac>: gives a song in FLAC as input (note: a full path is required)-codec:a libmp3lame: specifies to use the libmp3lame codec-qscale:a 0: controls quality,0being the lower value, it provides the higher quality possible-map_metadata 0: properly maps the FLAC song metadata to the MP3 song metadata (Source)-id3v2_version 3: selects ID3v2.3 for ID3 metadata<song.mp3>: specifies the exported song in MP3 (note: a full path is required)
- VBR Encoding was preferred to CBR Encoding.
-qscale:a 0is an equivalent of-V 0and produces an average of 245 kbps for each exported song.- More information about the settings is available here.
- In case other formats need to be supported for the exportation process, the
-map_metadata 0will need to be changed. - Indeed, mapping metadata to files with FFmpeg might be tricky and the parameter need to be modified, depending on the wished export format.
- For more information, please refer to:
The name “Audious” was taken from the HBO’s Silicon Valley. In this comedy television series, “Audious” is also a virtual assistant but seems to have more bugs!